

Hace un par de meses comencé con el curso Análisis & trading profesional (A&Tp) 16ª edición el cual me está pareciendo increíblemente formativo, no solo para conceptos de inversión si no financieros mismamente. Gracias al curso me he vuelto incluso más adicto a tener mi TradingView abierto a todas, pero sí que es verdad que me apena un poco como hay muchos screeners de pago o alguna manera para ver de un vistazo los momentos sucesos más importantes de todas las empresas de mi Watchlist.
Es por eso que pensé que los mercados financieros están constantemente generando señales, pero acceder a ellas no es para nada trivial. Por ejemplo, TradingView te muestra estas señales si sabes dónde mirar, pero revisar ~50 activos uno a uno cada día (como poco) no parece muy viable. Y, los screeners más avanzados que automatizan todo esto cuestan dinero. Debido a la falta de alternativas, me planteé construir mi propia lógica desde cero con el objetivo de entender cómo funciona por dentro y también para poder tener una herramienta de la que partir en caso de que quiera añadir más funcionalidades.
Tenía un poco de miedo de cuáles serían mis gastos operativos para crear algo así, pero tras investigar, recopilar herramientas open-source y ver los recursos que me ofrecen con una cuenta gratuita en la nube, pude crear un screener totalmente gratis.
El Problema
Las Medias Móviles
Hay tres señales que los traders profesionales miran todos los días y que serán las que vamos a conseguir:
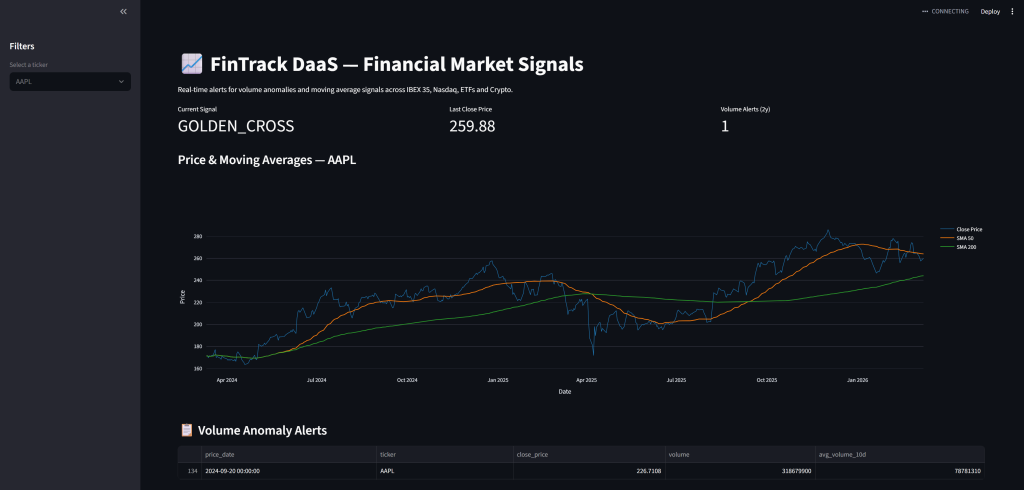
Las medias móviles (SMA 50 y SMA 200). Una media móvil es simplemente el precio medio de una acción durante los últimos N días. Si Apple cerró a 150, 155, 148, 160 y 157 esta semana, la media móvil de 5 días es (150+155+148+160+157)/5 = 154$.
La SMA 50 — media de los últimos 50 días — nos dice hacia dónde va el precio a corto plazo.
La SMA 200 — media de los últimos 200 días — nos dice la tendencia estructural, lo que está haciendo la acción a lo largo de meses.
Lo interesante no es cada media por separado sino la relación entre las dos. Cuando la SMA 50 cruza por encima de la SMA 200 se llama Golden Cross, señal de que la inercia reciente está superando la tendencia histórica, lo que para muchos traders sería una señal alcista. Cuando cruza por debajo se llama Death Cross, lo contrario.
No es una señal perfecta ni infalible, pero es una de las más seguidas del mundo precisamente porque mucha gente la usa.
El Volumen
Las anomalías de volumen. El volumen es el número de acciones que cambian de manos en un día. Si normalmente se compran y venden 10 millones de acciones de Santander al día y hoy se mueven 40 millones, lo más normal es haya ocurrido un evento (público o no) que ha tenido un impacto en la cotización de la empresa.
Esta métrica nos interesa mucho porque el precio puede manipularse o moverse por rumores, pero el volumen es más difícil de falsificar, pues requiere de dinero real moviéndose. De ahí se use como una herramienta de confirmación: un movimiento de precio con volumen alto es más fiable que uno con volumen bajo.
Las anomalías de volumen suelen preceder o coincidir con noticias importantes, resultados trimestrales, fusiones, cambios regulatorios, movimientos de inversores institucionales. Detectarlas antes de que la noticia sea pública no siempre es posible, pero detectarlas en el momento en que ocurren nos pueden ayudar a definir nuestra siguiente estrategia de inversión.
Nuestro sistema marcará como anomalía cualquier día donde el volumen supere el 300% de la media de los últimos 10 días. Un umbral arbitrario, sí, pero calibrado para capturar movimientos realmente inusuales y evitar falsos positivos. Igualmente, podéis cambiar el umbral al que mejor os parezca.
La Arquitectura:
Diseñé el sistema en cuatro capas, cada una con un cometido principal:
- Yahoo Finance → Python. Es una librería gratuita llamada
yfinancete da acceso a datos reales de bolsa sin necesidad de API key ni de pagar nada. Mi script descarga cada día el precio de apertura, cierre, máximo, mínimo y volumen de 50 activos. - Python → Google BigQuery. Los datos llegan en bruto a BigQuery, que es el data warehouse de Google. El nivel gratuito da 1TB de consultas al mes, para este proyecto usaremos menos de 30MB por lo que no habrá inconveniente. Los datos se acumulan histórico a histórico, sin sobreescribir nada.
- BigQuery → dbt. dbt es una herramienta que te permite escribir las transformaciones de datos en SQL, pero con una arquitectura que separa los datos brutos de la lógica de negocio. Las medias móviles, el Golden Cross, las alertas de volumen, todo se calcula con SQL directamente en la nube.
- dbt → Streamlit. Es una librería de Python que convierte código en una aplicación web sin necesidad de tocar HTML ni CSS. El dashboard lee directamente de BigQuery y muestra las señales en tiempo real.
Todo esto se ejecuta automáticamente cada día laborable (cuando el mercado está abierto) a las 22:00 via GitHub Actions sin ninguna intervención manual.

Lecciones Aprendidas
Breve mención de los problemas que me encontré, recomiendo antes revisar el ReadMe de Github para más contexto:
- El MultiIndex de yfinance. Cuando descargas datos de un solo ticker (ej: NVDA), yfinance en versiones recientes devuelve una tabla con dos niveles de encabezado en lugar de uno. No saltaba ningún error, simplemente los datos salían con una estructura incorrecta llena de NaN. Me costó un rato entender que no era un problema de los datos sino del formato. La solución fue decirle a pandas que solo se quedase con el primer nivel para las cabeceras.
df.columns = df.columns.get_level_values(0). - Los permisos de Google Cloud. Tuve que crear un Service Account con el rol de BigQuery Data Editor pensando que era suficiente para la ingesta de datos. Resultó no ser suficiente. Para ejecutar queries también necesitas el rol BigQuery Job User.
- La región de BigQuery. Creé el dataset en
europe-west1pero dbt estaba configurado para buscar enEU. Resultaron ser dos ubicaciones distintas en Google Cloud y dbt no encuentra el dataset si no coinciden exactamente. Se solucionó cambiando la dirección enprofiles.yml, pero me costó llegar a esa solución ya que di por hecho que estarían en la misma región.
Funcionamiento y Descubrimientos
Cuando el pipeline llevaba unos días funcionando, miré los datos de Apple y vi que:
- 20 de septiembre de 2024
- Volumen: 318 millones de acciones
- Media de los 10 días anteriores: 78 millones
- Flag de anomalía: TRUE
Tras indagar un poco en Internet, descubrí que ese día fue el lanzamiento del iPhone 16. El sistema lo detectó automáticamente, sin tener que realizar ninguna acción manual.

Posibles Mejoras
Tras tener el sistema completamente funcional, se ocurren varias mejoras que sería interesante implementar en un futuro.
Primero, el collector descarga 2 años de histórico completo cada vez que se ejecuta y luego sobrescribe los datos en BigQuery. Es ineficiente, lo correcto sería descargar solo el día nuevo en las ejecuciones diarias y el histórico completo solo la primera vez. Lo dejé así por simplicidad, pero sería prudente abordar el problema si pensara expandir la herramienta para evitar costes.
El resto son posibles mejoras. Como una funcionalidad de alertas activas. Lo ideal sería una notificación por Telegram o email cuando salta una alerta de volumen. También sería interesante poder elegir los tickers tú mismo, mostrar varios a la vez, ver las alertas más recientes de todos los tickers, etc. Con el tiempo iré implementado varias de estas opciones.
Pruébalo tú mismo
El código está en GitHub y el dashboard está desplegado en Streamlit Cloud. Puedes seleccionar cualquiera de los 50 activos y ver las señales en tiempo real sin instalar nada.
- Live Demo: santiagoborao-fintrack-daas.streamlit.app
- Código: github.com/SantiagoBorao/fintrack-daas
Estoy muy contento de haber llevado a cabo este proyecto, pensaba que sería mucho más laborioso y caro trabajar con datos financieros. Si estás pensando en hacer algo similar, mi consejo sería que empezaras ya y que dejes cualquier tutorial si tienes una base técnica más o menos decente. El primer error que cometas o la documentación que leas te enseñará más que cualquier tutorial.
Muchas gracias por el interés dedicado, espero que este proyecto pueda servir de referencia.


0 Comentarios